Every Page is the Opinion Page Now
Have you noticed, too?
Start reading an "article" on some information, news,infotainment or whatver they call it today web site and you quickly notice it's an opinion piece. The byline is not the headline -- the byline is the writer, and is formatted like it was the reporter. As-if it was "reporting".
An opinion piece showcases the author. The auther of an opinion piece is very important -- the validity of the opinion is partly judged by the integrity of the author.
We read "10 Essentials for a Successful Dinner Party" by Martha Stewart. We read "How to invest in Stocks" when it is written by a rich, successful investor. But do we read "How to Raise Healthy, Happy Children" authored by a known psychopath who tortured and murdered her children?
These days we are seeing unqualified (and even disqualified) people writing our articles, published on major brands. Discernment has left the editorial building... the integrity of the advertising department has trumped the editorial offices, ethics, and common sense.
The fraud has progressed even further -- we almost routinely see discredited posers shake off the public criticism and resume posing, often shortly after public scandal. That rich guy who wrote the investing book was actually poor, until the book went viral? Well now he is rich, and nobody cares about his fraud. We can't wait for his next book, or a chance to see his rich house on that TV show about the rich and the famous.
"Brand is how you sort out the cesspool..." was one of the dumbest things ever said is the search world. While it may have seemed smart to listeners at the time, those listeners didn't know what Eric Schmidt knew about search. Given what he knew, it goes doan as a dumb AF expression -- Google shifting to reliance on "brand" merely shook the tail of the dog, rather than propel it forward. Brands cashed out, brand integrity and differentiation dissolved, and the ad money ethics supplanted editorial, or the very principles that used to define "brand". Did search advance? Nope.
One glance at the author of that statement reveals plenty... I'll leave it to you to discern the character and integrity of Eric Schmidt.
If you study marketing and search today, especially if you are involved in the SEO and Competitive Webmastering arenas, these aspects of public communication matter a great deal. For SEO, I believe they are literally everything. Labels like EEAT and "content" are nonsense, and we should use the authorship to discern the opinions we see, regardless of the sell-out brands behind the publications.
Leaders must lead, or they are not leaders. Leaders must have committed followers, or they are not leaders.
A self-proclaimed leader with large numbers of non-committed, casual followers is not a leader at all.
Recently published to the Ample. substack:
In her book "Outsmarting the Sociopath Next Door", Dr. Stout notes 2 attributes of certain professions that are "extremely and specifically attractive to sociopaths". The first is "to have interpersonal power over a number of people who will seldom question you". The second is "privacy", defined as a "setting that is effectively closed to outside observers".
Doesn't this seem to apply to Google, where the search "algorithms" (and all components of the search engine conglomeration) represent a privileged position of power over people? Search is an interpersonal setting, because when the individual executes a search, Google uses privileged a-priori knowledge of the searcher's other online activities and behaviors to profile them, and to customize...

Subscribe to Ample. on Substack if you want to follow along:
A new section for quick thoughts that may or may not be active engagements.
Penses
- April 21, 2024: So much to say, but no interest in saying it. Is this how censorship works? Is the chilling effect of oppression of expression that effective? I'm starting to believe that it is, indeed. Jesse was smart to focus on his particular project; he will do well if it works out. As the coffee brewed this morning, my thought about Jesse (prompted by that awesome photo of "the dog", lol), I wondered about Marcus... where is he now? Well, married, for one thing. Second thing I noticed is he lives the modern life online (and captured quite a beautiful bride) -- both outside of my expectations for him, based on what I knew (and I know nothing about him since then). A geek, a dork, a brainiac, a "solo".... with nearly sappy IG etc posts floating around the global social circles, akin to the way awkaward Silicon Valley dorks did it before Jobs. To Jesse, life is not a game but a surf to seek harmony with... while I am going to guess that for Marcus, life is indeed more of a game, with points, levels, and end bosses. One has all the money, and is buying happiness? The other appears to need only money. Life lessons!
- April 17, 2024: "Pull received nothing" and the significance of free association of memes. This deserves a blog post someday. Definitely on of the more effective techniques for evaluating job candidates, especially in SEO.
- April 10, 2024: Listened to an interview where the guest was a real jerk, yet honestly didn't understand why people didn't want to relate directly with him (choosing instead to go through intermediaries). Even his associates on a company board avoided dealing directly with him. In the same conversation, he repeatedly described the ways he manipulates businesss deals in order to gain access to people, which he referred to as "building relationships". Not ironically, I note the interview host was a similarly likeable character, so I am sure they each, in turn, validated each other's exceptional status as players in their industry.Future Essay : SEO Research - The Study of Wanting, a Human Behavior.
- April 2, 2024: Props for some Hustlers - oh how I do amire the con man. WHAT?? Yeah... the legit hustler, not the slimy ones. I'm talking about the Robert Redford/James Caan style hustler who would eagerly inform you that you'd been taken, because they had integrity. They tricked you, stole from you, but you deserved it because you were capable of knowing better but... for reasons... you LET THEM do it. And, becaused they have integrity (are honest, lol) they want you to know how they did it (if you want to know -- which is a sign of you're waking up). HOWEVER, I am not referring to the pedo-living-in-Thailand kind of hustler. Those guys need to come clean with public aplogies and ask for forgiveness, which always includes evident commitment to changing. Different breed, those miscreants.
- March 28, 2024 : There certainly are a lot of John Andrews on the internet now. I was one of the first few, and for many years there were but a dozen or so current ones revealed in Google search, plus a half dozen historical figures. Watching my name was a lesson in Google search -- I could "see" how indexation and relevance played out. As social media rose, Google search remained readable to my SEO scrutiny - I could "see" how Google managed blogging, web sites, content-stealing aggregators like Wikipedia, and discrete platforms like Facebook and Twitter. Not so easy today: Although the Google bias is still clearly evident, the lines between platforms and how they are managed is not clear. Once could say that Google (finally?) has started indexing and ranking the web, instead of select platforms. Of course one side note has to be that Google is CLEARLY choosing to demote, if not ignore, "regular people's" content while favoring certain sources.
Something I published in 2014 : with an updated chart from 2023 (at end)
Welcome to Dysphoriana. It’s where we live now.
Dysphoria is commonly defined as a “state of unease, or generalized dissatisfaction with life“. The word dysphoria is derived from the Greek dusphoros or dysphoros, which translates as “difficult to bear“.
We, my fellow Americans, are living in a dysphoria : a state of difficult-to-bear angst, or psychological discomfort. And it is effecting everything we do (i.e. our behavior).
In the free-market-capitalism, rule-of-law society we have here, the impact of this dysphoria is severe. Because our systems of commerce and governance adapt to our behavior as consumers and voters, our behavior is changing everything about our society…just as our society is cashing in on our dysphoria.
Marketing is pandering to our state of dissatisfaction and generalized sense of angst, telling us with increasing frequency and convincingness how right we are to feel that way.
Our government and the big business behind it is also cashing in. Let’s face it : a fearful people is easier to control. A group of emotionally exhausted, disconnected lost souls is easier to steer, and easier to monetize.
Sadly, these influences are increasing the depth of our dysphoria. It’s a vicious cycle of destruction. The downward spiral erodes our core values; the very things that make us human.
As the dysphoria erodes our individual identities, it consumes the hope we have for a brighter future, erodes our personal sense of self worth, and devalues our respect for others.
People are stupid. People are idiots. Everyone is in my way, preventing me from being the good, successful me I was born to be. It all sucks, and we’re all doomed.
I call this world Dysphoriana.
Chart of media mentions for "dysphoria" since 1950 or so showed a steady rise from the 1950's up to 2014.
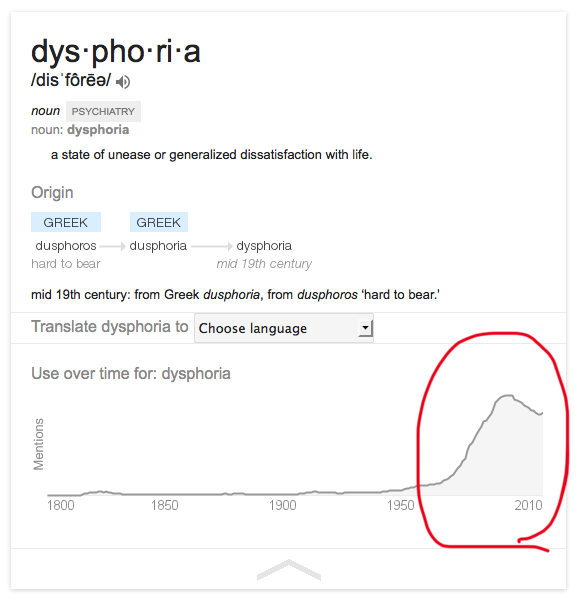
2023 Update: Looked what followed... from 2014 until 2023 -- a large secondary peak.
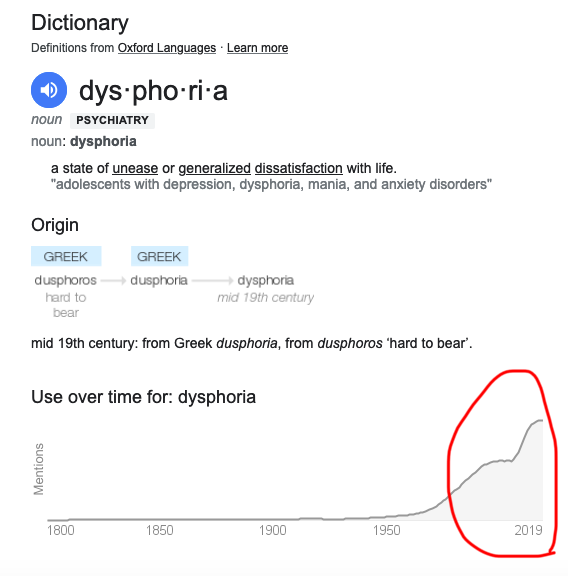
Future Posts:
- "..you'll find out the less an arse*ole you are the less people are against you" - some fool on Hacker News, June 2023. THIS is how civilization falls, while the fools sleep.
- There's a podcast show in the works, and it covers a lot of what modern "SEO people" consider to be SEO. And it'll be fun, based on what I've seen so far. Are you ready? I'm not.. lol... because the more we do and the more we talk with producers, the odder things get... including getting farther from the reality that is performance-based web publishing. But I'll figure this out... and finally produce the show I've always wanted to produce.
- The local web training seminar series has expanded and will take on a "weekend" character going forward, with multiple sessions of varying level, offered sequentially at the same venue over several days. I need to fill the room for more complete feedback, so there may be some promotion. Free seminars are odd in that they draw a strange crowd on the first day, but if meaningful, some very interesting characters show up the second session. It's just fun for me, but for reasons unstated, it's about to get a little more "interesting" ;-)
- Note: Bring back some classics like /fake-reviews-cesspool.html, wednesday-fun.html, seo-consulting-2.html, google-chrome-privacy.html, health-vault.html, google-agency.html, google-go-words.html, google-toolbar.html, free-seo-tools.html, panda-update-seo.html, trailing-slash-seo.html, seo-zend-framework.html, seo-correlations.html, nytimescom.html
Where are the Old Posts? So many are missing..
Most old posts are deleted. They had value to me when current, but the value proposition changed when they aged, towards value gained by others (such as search engines and LinkedIn Professionals). Therefore, old essays are routinely deleted.
Also worth noting : my legal team pursues those who publish my copyrighted work elsewhere, and my reputation management team takes on all cases where those kind, legal efforts fail to get the content removed. After all, thieves only steal things if the gains exceed the costs of stealing them -- hence we make sure the costs associated with stealing are, shall we say, excessive.
John Andrews and Johnon.com
Someone once told me that when they hear a conference speaker describe some SEO issue, they prioritize finding out "what would JA do..." as their next step. This blog was named "JohnOn" because it represents my opinions "on" a variety of topics (most related to entreprenuring using the web, in competition with other publishers).
A few selected references noted from a brief period when I was public with my SEO thoughts (a random few of many -- I see no reason to list them all here):
- Guest on a segment of Webmaster Radio, where I was literally grilled by the host on a variety of SEO topics, as if he was capitalizing on his chance to get some free SEO consulting he could use for his own SEO consulting business. He admitted during the interview that, yes, I really did know a lot about SEO. LOL
- Quoted in Bloomberg Business Week, on Google's and Demand Media's co-dependency
- "John andrews is one of the smartest industry folks I've ever met", said Marty Weintraub, the author of Killer Facebook Ads (in the book).
- Cited as an essential resource in the book "111 SEO Tips" (published in German)
- During his keynote at the SMX Search Marketing conference, Danny Sullivan -- owner of the conference and one of the best known public figures in the search industry, mentioned my name 14 times(!) It was very strange experience to have the keynote speaker cite my essays, my opinions, and my SEO activities over and over in front of his audience, while discussing the state of the art of SEO and search marketing. We were not friends. I did not support him as a leader in my field, and he did not win me over with his flattery.
- Cited for defining competitive website optimizing as an effective practice, in the book Website Visibility: The Theory and Practice of Improving Rankings
- "John Andrews is one of the smartest, most perceptive people in search marketing", noted by search conference organizer, in a profile published in advance of one of my rare conference appearances.
- Many very kind references have been passed along by clients over the years. Said one business owner to a friend who was looking for a trustworthy SEO consultant: "We have worked with John Andrews in Seattle for two years now, and are very pleased. He is very high-end as an SEO consultant, but for some reason he tolerates us bothering him month after month. He's very advanced, but still knows how to communicate (rare!)"
- Invited and sponsored to attend/speak at numerous conferences, some of which I accepted and attended. These include NamesCon, the TRAFFIC domain name conferences (several times), Search Engine Strategies (SES), Search Marketing Expo (SMX-Advanced), Domain Roundtable, Search Fest (portland), and others.
- Recommended as one of 3 resources for business people seeking top-tier insights into web publishing: "John Andrews.... you'll need to read between the lines a bit as he's not going to just lay out every tactic or shift in black and white. He'll suggest things to consider and in general he's way ahead of the curve. Read everything on his site and sign up for his newsletter."
- I have known 2 former Rock Stars who became web marketers/SEOs, and this compliment was published by the one who went on to win a lot of web marketing awards: "Some writers have more guts than others...John is fearless and totally gets it. There was some buzz in 2010 about how effective certain SEO firms, known for correlation studies, are at reverse engineering Google’s algorithm. This post from John Andrews is the definitive one to our mind, and challenged other thought leaders in respectful and compelling ways."
Quoting My Self
"To an experimentalist, everything is an experiment. Observations are rarely what they appear to be."
"Confidently chase market share as an SEO success metric. Document your many assumptions (of course), but do boldly estimate market share based on real data you collect on queries, user distributions by intent, geo, and other factors. Always, always pursue higher market share."
MediaPost highlighted my "Healthcare Search Marketing" SEO notes, so I ranked myself into position #1
MediaPost highlighted a blog post of mine about healthcare search marketing consultants and agencies. I had noted that ranking for a healthcare search term was not always associated with servicing the searchers finding the top-ranking result. If you were good at SEO you could rank for a term, even if you didn't deserve to be top-ranked for that term (https://www.mediapost.com/publications/article/68284/top-ranked-search-firms-all-aint-the-same.html).
After that, I decided to rank myself for "healthcare search marketing" and promptly earned the top #1 position. I held for over a year. During that time, I received emails from professionals in the health space, complaining that I had insulted them. Remember, this was back when people actually believed Google was a benefactor for the web. Some successful yet amazingly ignorant programmers back then were so sheltered, they openly hated on SEO (even technical SEO), preaching that you could rank for relevance by just-making-good-content (Cal Evans, "Just Say No to SEO", July 2007 updated Feb 2019).
On Censorship...quoted from an interview
Prior to Threadwatch I mostly stayed out of forums and the like, due to frustrations I felt dealing with those who quietly "managed the message" as moderators. People only see what gets published, and they want to believe it’s the whole story. If they are told "we only edit out obscenities" then they believe that what they see is what was written, perhaps sans obscenities. Sadly, that is far from the truth. Posts are edited and deleted as needed to manage discussions, and often there are strong agendas at work behind that process. Threadwatch started as a place that promised not to do that, and it didn’t. I was one of the first 3 editors of Threadwatch, and I didn’t even get any instructions for doing the job. It was simply assumed that we would only fix problems, delete obvious spam and bring questionable issues up for discussion. Everyone had a voice if they exercised it. If there were too many UFO posts the community complained to the posters before any moderators did.
On Helping Others with SEO as a Consultant, quoted from an interview
I follow the consultant model in my business, rather than an agency or practice model. That means I focus strategically on those aspects of search marketing (and competitive webmastering) that bring business success rather than simply SEO success. I believe that a business looking to succeed in search marketing is actually looking to succeed online in general, not just gain more search traffic. Unfortunately, many businesses don’t have that general online success model worked out yet, and their SEO efforts fail to perform cost-effectively even if they succeed based on SEO metrics alone.
Fortunately, the same knowledge an SEO needs to achieve SEO success can be used by the business itself to refine the online success portion of the overall Internet marketing equation. This can be done at the same time, and with relatively little incremental cost, via the consulting model. I hope to demonstrate that by showing how working effectively with an SEO at the strategy level can guide you towards overall online success, while simultaneously empowering you to effectively manage your SEO engagement and empowering your SEO to succeed on your behalf.
On Competitive Webmastering...quoted from an interview
Much of what we do as search optimizers is really just good web publishing, following proper technical and usability guidelines. But as search becomes the default access channel for Internet users, building for search (search friendly publishing, or SEO) is actually necessary.
And that is a self-reinforcing thing -- the more search works for people, the more they use search. If every webmaster optimizes, they all need to optimize further, in order to compete. So if you expect to be competitive today, you need to be search optimized. If tomorrow we have something new that is more important than search, we webmasters will need to accommodate that as well. In general, you are a competitive webmaster.
On Content
Content. That word is so important. And when you read it.... like when you read it above, you believed more than the type expressed. You projected into the typed word on my web site, your own committed belief of what it meant. And not just the meaning, but the pronunciation, as well.
Chances are very good that you read "KAHN-tent" as in the content of this web site post. But I wrote "content" pronounced "cunn-TENT", meaning at peace, pleased, satisfied, or perhaps some flavor of happy.
Stop projecting your own meaning into other people's words! Read what I wrote, not what you think I wrote. You look like an idiot when you do that! (I'm kidding... but the point is in there: the reader consumes your content within the context of their own belief systems and contextual perspectives, These factors are usually outside of your control. Managing that, is akin to managing risk, which is essential to any business endeavor).
*If there is a way to contact me, it is provided at the bottom of the page.
Update Advisory : There are certain disordered personalities in today's SEO world who not only don't care about any of the things that Daddy should have advised them to be careful about in life, but for whom negative attention is an actual goal. Rather than describe such individuals here, I will simply say you know who you are. And, often, so do I.
Normally it is a bad idea to provoke careless, deviant personalities. Many of you out there in SEO world choose to actually pay them to leave you alone. I have witnessed this, and feel more remorse for your sad soul than theirs -- you at least acted out of free will, when you did wrong. Shame on you.
As for the deviants who seemingly enjoy causing trouble, often for attention-of-any-kind, I have a specific warning. I have worked in behavioral health and rehabilitation (both physical and mental) for probably as long as you've been alive. My "other" personal activities have typically engaged with very high functioning, and very high "level" individuals of all sorts of persuasions and personality types. The kind of functional people who get things done -- including the Dirty Work, and especially swift, effective, typically permanent actions that eliminate competition. I do not condone their behaviors, mind you, but I have worked alongside them, advised them on matters of which I have insights, and received from them great learnings of how things are actually done in this world.
"Revenge is a dish best served cold", they advised me, time and again. Yet, my own professional work, with physically altered individuals such as those with locked-in syndrome, and mentally captured individuals such as those addicted to methamphetamine, has taught me there is no greater hell than the one that inprisons you.
The best reaction to an unjust assault by a deranged individual, such as a suffering young SEO who acts out against others online because he feels he can remotely do harm without getting caught, is charitable investigation. Seek to understand his hell. What is the source of his own personal angst/anger? If after determining he cannot be helped out of his misery, you decide that a reaction is necessary, add another lock to his prison cell door.
After charity comes mercy.
So if you choose to meddle remotely, you will gain my full attention -- and trust me, I have a lot of free time -- with which I will attempt to get you local help. That's the charitable part. You clearly need help, so I'll focus on you getting the help you need and deserve. Endlessly. Through every available avenue -- your local priests, Evangelical ministers, psychiatrists, psychologists, counselors.... street outreach teams... suicide counselors...every resource from the top of the food chain (police, your mom, etc) all the way down to the uncredentialed and poorly-regulated former heroin addicts who think they know how you think. I have direct access to these very effective tools, and will make sure they ALL understand how important it is to help you... and if necessary, how rewarding it could be for them to at least try with all of their might.
Clearly, you have better things to do than earn such a response?
It's not Me, it's You.
My Word of the Day today is ostensibly. Do you know what it means? Or are you one of those moderns who say "I know what it means when I read it or hear it in a sentence, but I can't give you a formal definition". We get so much BS from those egotistical, ignorant moderns.
The title here is a twist of a phrase. During my lifetime experience, the phrase "It's not you, it's me" grew during the Friends generation. The Friends era was anchored temporally by the TV show "Friends", which showcased a culture quite different from my own post-Boomer, pre-Millenial culture. They tried to avoid conflict. They evolved a neo-pagan, self-deprecating culture which, due to inevitable aspects of human nature, fostered passive aggressive behaviors, all-in megalomania, and victimhood -- all of which we now see quite commonly in our society today.
I'm of a more inquisitive, scientific background. I know that actually, in fact, it's usually not me, but you.
Humans tend to behave as they have before. You can bet on that. The era of "I'm OK, you're OK" was before my time. That age of Valium and relatively low THC marijuana paralleled cultural rot and hedonism: sex, drugs, acting out, and giving up. Boomers, yes, but not all Boomers.
So, keep this in mind: if your past behavior (by my witness) was X or Y, then I (just me.. not necessarily anyone else) will expect that you are likely to behave the same way in the future.
Reason is a human behavior essential for survival. And reason requires that consideration.
If you're now thinking to yourself that my position here is bigoted, or suggests that I think people can't change, or that I fail to provide allowances for people to recover or otherwise repent from past errors, then you're being stupid. And that is a fact. Of course I respect that people can change. But I also expect relapse, as is reasonable to expect, given truthful observation of human history and human behavior.
Remember, this is for YOU. You have established a reputation, and a pattern of expected behaviors. Do you even know what they are? In context?
I am your context. How I witnessed you behave, is how I expect you will behave. Have you changed? Are you different now? Well, that might be awesome! But how would I know? I don't... but I do know who you were before, and I will very reasonably expect more of the same from you.
The Proper Definition of a Rat
For all the GodFather fans out there (the original, not "II" lol), we now have an update on the proper definition of a rat.
"you give up people around you, to save yourself (from a prison sentence). The people that you were in bed with, the people that you trusted, that trusted you -- to save yourself, you bury them, whether they were your friend or not. That is not something that you're supposed to do" - Michael Franceze
Now you can debate whether the guy who violated his oath and left the life is a rat or not, but like everyone else you have to work within a proper definition of "rat" so here we are with one that not only works but seems to match the working definition defined by decades of street life.
Not everyone is courageous. No everyone is wise. Not everyone has the skills needed to manage every situation. But no one, ever, should be a rat. It's not just ugly, or disgusting, or wrong. It's quite simply inhumane. Which is why the rodent was chosen as the model.
Do whatever you can to not be a rat. There is nothing better for you to do.
Need to reach me? Call me, or text me, or hit me up on Slack, Discord, Telegram, or other. I'm not active on Facebook, nor am I on LinkedIn.
If you need my contact details or phone number, just find someone you know who already has it, and ask them for it. #simple.
If you discover that you don't know anyone who knows me, well... sorry about that. Maybe you can you ask every SEO person you know "Do you know how to contact John Andrews?". That sometimes works well.
For everyone else, try emailing me at one of my domains, like johnandrews.org or johnandrews.com or this site JohnOn.com, or maybe andrews@ hey.com.

{kind=link}
- latest-fishing-tampa-causeway-2502.jpeg
Fishing Courtney Cambell Causeway
- latestx.jpeg
Daffodil
- latest-fishing-tampa-causeway-2517.jpeg
Fishing Courtney Cambell Causeway
- latest-fishing-tampa-causeway-2522.jpeg
Fishing Courtney Cambell Causeway
- latest-fishing-tampa-causeway-2491.jpeg
Fishing Courtney Cambell Causeway
- latest-squal.jpeg
Squalicum Harbor
- latest-harbor.jpeg
Squalicum Harbor
- latest-everettsky.jpeg
Everett Harbor
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The Dawn of the Disinformation Age
We can haggle about the exact month or quarter later, when we have historical hindsight, but as of right now I'm calling it: the Information Age has ended, and we are now in the Disinformation Age. Fake News is not the Reason
Chris Hedges did a good job describing the Fake News phenomenon:
The object of fake news is to shape public opinion by creating fictional personalities and emotional responses that overwhelm reality. Hillary Clinton, contrary to how she often was portrayed during the recent presidential campaign, never fought on behalf of women and children—she was an advocate for the destruction of a welfare system in which 70 percent of the recipients were children. She is a tool of the big banks, Wall Street and the war industry. Pseudo-events were created to maintain the fiction of her concern for women and children, her compassion and her connections to ordinary people. Trump never has been a great businessman. He has a long history of bankruptcies and shady business practices. But he played the fictional role of a titan of finance on his reality television show, "The Apprentice".
The rise of Fake News isn't responsible for the Dawn of the Disinformation Age. It's just one very obvious symptom of the establishment of the new age. Fake News has been around forever. When I was a kid, it was gossip, and rumor. The internet has amplified it, and made it more powerful. The corrupt press has adopted it as a tool.
We all saw that part coming... the rise of the "television Anchor Man" who wasn't a real journalist. The dawn of "cable news". The embedding of media and elimination of field journalists & photojournalists. The consolidation of newspapers. The success of tabloids in Britain, as newspapers struggled. The firing of news staff, replaced with new people charitably described as early-career "writers". The move from professional photography to "hey wanna-be celebrity news correspondant, don't forget to bring your iphone to get some pics".
Corrupted Information Distribution
Now we also have the corruption of information distribution, via agendas pursued behind the scenes by Facebook, Google, and Twitter, and others. Google has long hidden its manipulations behind a secret "algorithm". Facebook hid its manipulations behind the Timeline interfacess. And Twitter..well, I guess poor Twitter couldn't come up with anything better than the outright censorship they've implemented.
The Blogging Revolution didn't last long. The corrupt entities worked to kill it technically, while simultaneously shifting incentives away from independent reporting.
Google manipulated commenting, compartmentalized indexation & ranking of blog-published content, and killed non-Google distribution efforts. It raided the RSS world for virtually all the leadership talent, and then aggregating the feed users via its subsequent virtual monopoly on RSS feed reading and distribution. Then Google killed off its own popular feed reader abruptly.
Facebook's core agenda competes directly with blogging, so simply advancing with billions of IPO dollars worked to kill blogging. Similarly, Twitter's parasitic "microblogging platform" eagerly sickened the host.
Group Think and In-Group Preference
Probably the biggest colluding factor aiding the rise of the Age of Disinformation seems to be Group Think, also known as "in group preference". That part is YOU, dear reader. When you echo only sentiments you agree with, whether or not they are based in fact or even reasonable, you contribute to the group think that appears to be reality to so many who know even less than you.
All the Trump comments are perfect evidence of this. I won't go there in this article, but if you have a firm stance pro or against President Donald Trump, you are likely part of the problem.
Self-Medicating
In America, the common man has been abandoned by the press. As individuals permit their livelihoods and lives to be placed at risk, as a consequence of they themselves choosing not to investigate or reason through often inaccessible facts, they feel the vulnerability. In response, they are forced to cope with fear and uncertainty, even as they go about their regular business.
Fear and Loathing in America
Ambient fear and uncertainty takes a significant toll of the psyche.
Operating under fear, individuals do not think more reasonably, act more rationally, or listen more astutely. Nor do they react more appropriately.
On the contrary, manipulated by fear they over-react, shut down, deny threats, take drugs to manage anxiety, and sometimes scream out in anger, resentment, or despair.
Have you ever tried to console a 3 year old whose balloon has escape and is visibly soaring away, high in the sky? Nothing will ease the pain, except a promise of immediate attention to the task of getting another one, right now. And sometimes it needs to be a bigger, better one.
That promise is often a lie... unless the little tyrant has previously proven he really means to wreck the world unless he gets his balloon back, right, now.
Reference: I don't agree with a lot Chris Hedges writes these days. I see him as biased; swayed by disgust with his journalism peers, and perhaps disappointed to the point of depression, if not actually crippled, by his loss of access to quality information. But, within this essay I found the above commentary on Fake News http://www.informationclearinghouse.info/46075.htm
— Originally published to https://johnon.com/1135/the-dawn-of-the-disinformation-age/, last revised Feb 21, 2019